
一
去年年底的某个晚上,我坐在书桌前翻开一本三个月前读过的认知科学教材。
我记得读那本书的感觉。荧光笔划了很多线——黄色的、橙色的、绿色的。页边写满了"精彩""重要""核心"。我记得合上书时那种饱足感:嗯,这本我吃透了。
但那个晚上,当我试图向一个朋友解释书里的核心概念时,我张了张嘴,什么都说不出来。
不是忘了某个细节。是整块的东西不见了。像一栋楼的地基被抽走,连碎片都没留下。
我重新翻开书,看到那些荧光笔痕迹——它们还在,但我跟它们之间已经没有任何联系了。那些标记像是另一个人留下的。
这个感觉让我非常不舒服。不是因为忘了——谁都会忘事。让我难受的是那种"被骗了"的感觉。读的时候明明很顺,划线的时候明明觉得自己在"学"。那种流畅感从哪来的?它为什么会骗人?
二
2015年,认知心理学家 Soderstrom 和 Bjork 做了一件挺重要的事:他们把 performance 和 learning 这两个词拆开了。
Performance 是你学习当下的可观察表现——答题正确率、反应速度、那种"我懂了"的主观感觉。Learning 是持久的认知结构改变——三个月后你还能不能用,换个场景还能不能迁移。
这两个东西在日常语言里几乎是同义词。但在认知科学里,它们可以完全背离。
Roediger 和 Karpicke 在 2006 年做了一个实验。两组学生学同一份材料——一组反复阅读四次,另一组读一次然后做三次回忆测试。五分钟后考,反复阅读组更好。一周后再考,做测试那组大幅胜出。
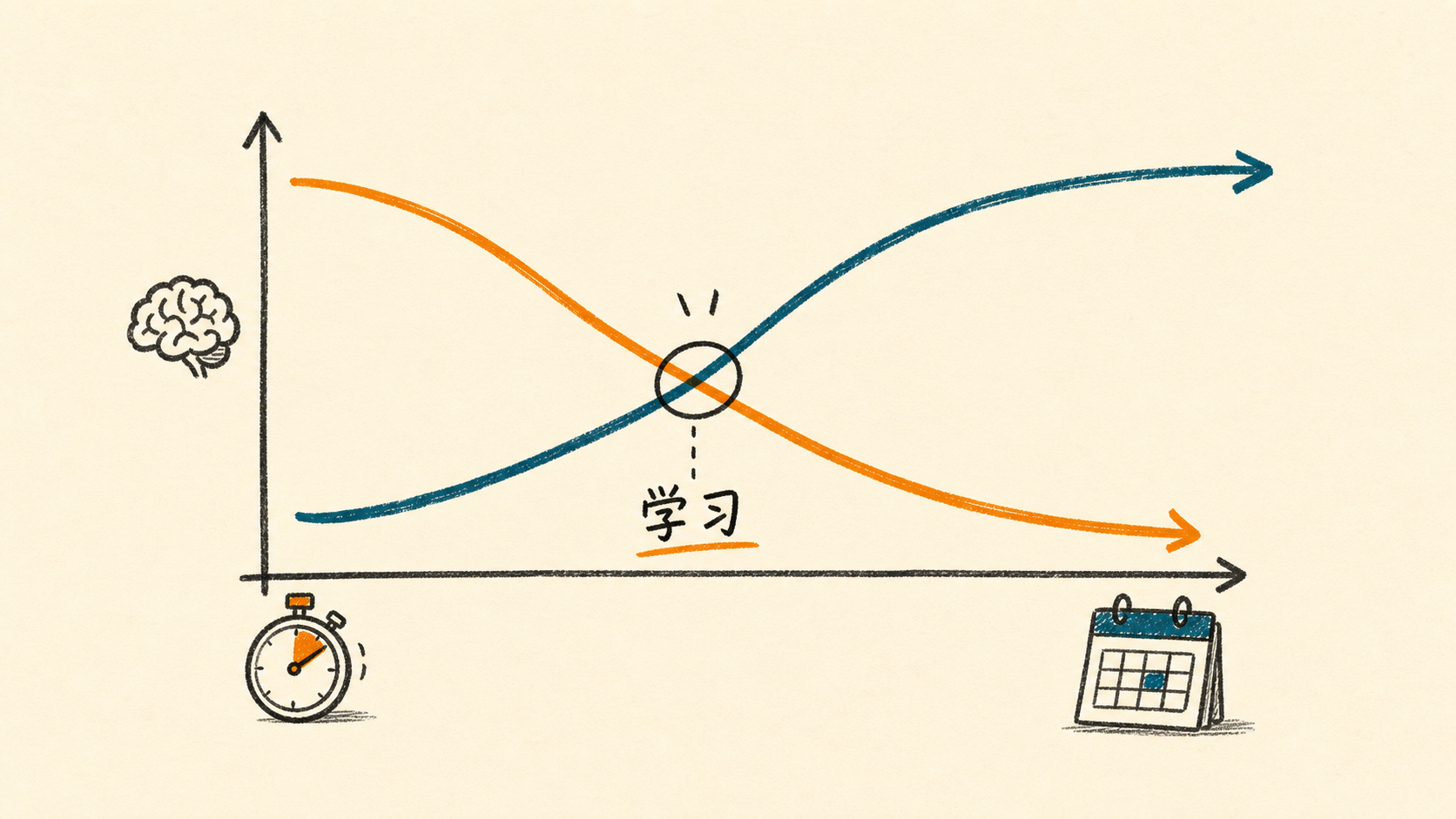
五分钟后的成绩是 performance。一周后的才是 learning。它们指向相反的方向。
回到我那本满是荧光笔的书。我当时做的事情——反复阅读、划线、写"重要"——全都在提升 performance。每一次重读都让我对材料更熟悉,产生更强的流畅感。但这种流畅感只是识别信号——"这个我见过"——不是理解信号——"这个我能用"。
坦率的讲,我在做一场表演。观众是我自己。
流畅感的代价
拖动时间滑块,看两组学生学完同一份材料后,得分如何随时间变化。
三
如果你做过机器学习,这里有一个你一定认识的结构。
你训练一个模型,在训练数据上表现完美——准确率 99%,loss 趋近零。你兴冲冲拿去跑新数据,崩了。模型记住了训练数据里的噪声和表面模式,但没提取到真正的规律。这叫过拟合。
反复阅读时我的大脑在做什么?它在记住那些具体的句子、具体的页面位置。就像过拟合的模型记住了训练样本的每个细节。当我翻回同一本书时,这些记忆让我产生"我知道这个"的感觉。但换了情境——需要对别人解释、遇到类似但不完全相同的问题——什么都拿不出来。
训练集上的高表现 = 学习时的流畅感。测试集上的崩溃 = 三个月后的张口结舌。
不过这里有个重要的限定。人脑不是神经网络。机器学习里的过拟合是一个统计问题——模型复杂度和数据量的不匹配。而我的"假学会"更多是一个策略问题——我选择了错误的学习方式。这个区别很重要。但两者共享一个深层逻辑:系统适配了局部环境的表面特征,没有提取出可迁移的深层结构。
那怎么办?
四
答案反直觉到让人不舒服。
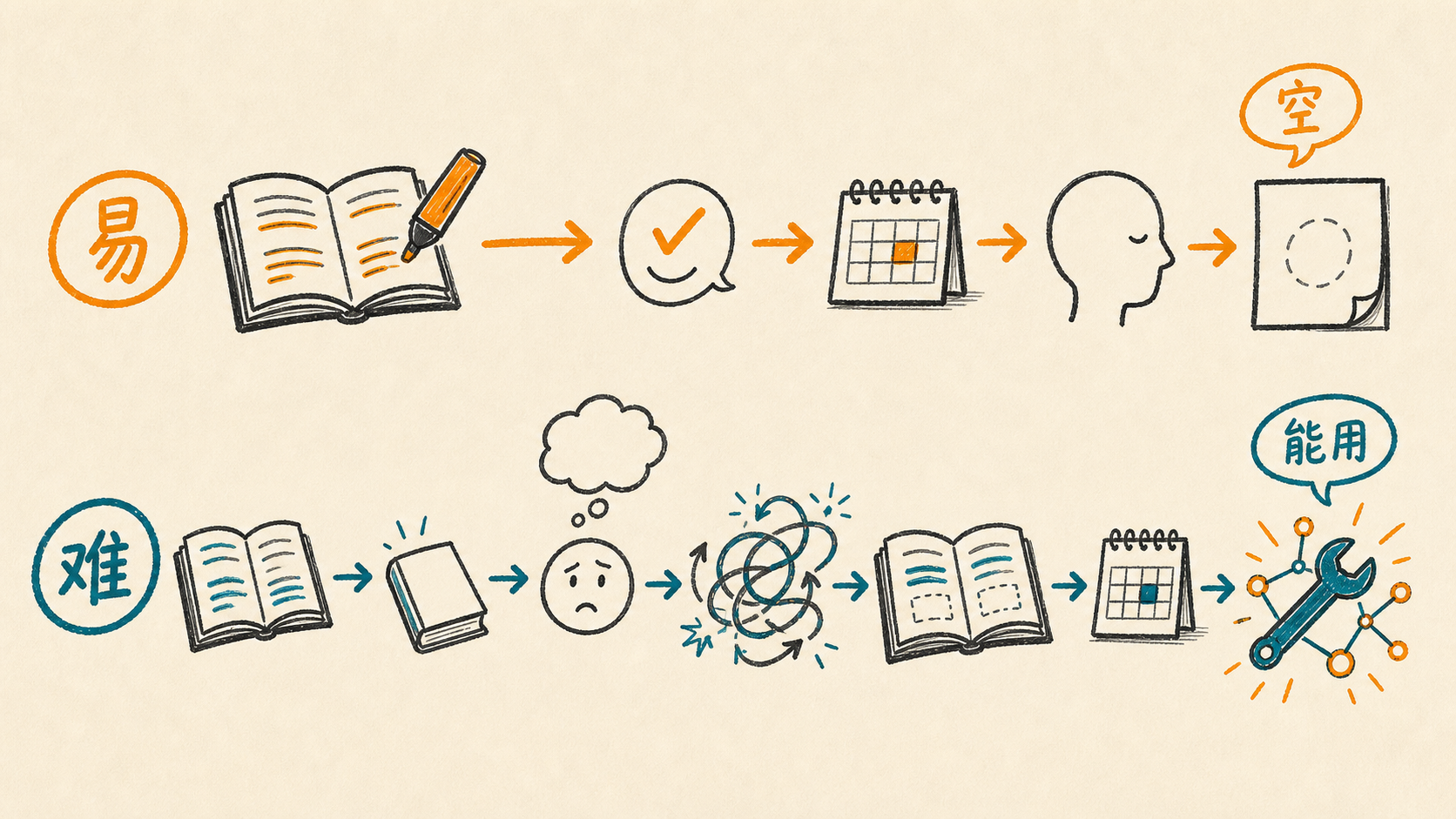
Bjork 在 1994 年提出了一个概念叫 desirable difficulties——合意困难。说白了就是:学习过程中刻意给自己制造某些类型的困难,短期内表现会更差,但长期来看学得更深更牢。
具体有四种经过反复验证的做法。间隔——别集中突击,把学习分散到不同时间,每次重新捡起来都有点费劲,这个费劲是好事。测试——别光看笔记,合上书试着回忆,回忆不出来没关系,那个挣扎本身在加深编码。交错——别把同一种题做一百遍,把不同类型混着做,混乱感是好事。生成——别等答案送到眼前,先自己试着给一个答案,哪怕是错的。
这四种做法有一个共同特点:它们让学习变得更难受。
和我那个荧光笔的晚上形成了精确的对照。划线时零痛苦、纯流畅,三个月后什么都不剩。如果当时合上书,强迫自己不看地回忆核心要点——哪怕只想起来 30%——那 30% 可能现在还在。
说真的,这个发现让我生气。不是对研究者生气,是对自己。我花了多少时间做那种"舒服的学习"?那些读了就忘的书、刷了就过的课、记了就丢的笔记——它们给了我"我在进步"的幻觉,但什么都没真正留下。
五
让我觉得这件事不只是一个学习技巧的是,同一个原理在完全不同的领域被独立发现了。
免疫学里有疫苗。你注射一个弱化的病原体进入身体——显然让身体"不舒服"了。但正是这个经过精心设计的困难,触发了适应性免疫应答。身体不只是扛住了这次攻击,而是变得比攻击之前更强。加强针的间隔——两针之间等几周——和间隔学习的逻辑一样。
运动生理学里有超补偿。肌肉在训练后受到微损伤,恢复过程中蛋白质合成增加,肌肉变得比训练前更强。没有困难就没有生长。但过度训练会受伤——困难必须适度。
机器学习里有 dropout。训练时随机关掉一部分神经元,逼模型不能依赖单一路径,被迫学习更鲁棒的特征。训练表现变差了,但泛化能力变强了。
四个领域——认知心理学、免疫学、运动生理学、机器学习——四群互不认识的研究者,独立走到了同一个地方:系统通过应对适度困难而变得更强。前提是困难不超过系统的恢复能力。
Nassim Taleb 后来给这个通用模式起了名字叫反脆弱——不是抗打击,是被打了之后变得更强。
六
但"越难越好"是一个很危险的误读。
Bjork 说让学习更难。Sweller 说减轻认知负荷。看起来说反了。但想了一阵子我觉得调和点其实很精确:困难分两种。
一种是让你不得不深层加工信息的困难——合上书回忆、打乱练习顺序、自己生成答案。这是好的困难,它迫使大脑做更深的编码。另一种是纯粹浪费工作记忆的困难——教材排版混乱、指示不清、信息过载。这是坏的困难,什么学习都不会发生。
Vygotsky 将近一百年前就说了:学习必须落在"最近发展区"里——就是那个"自己够不到但有人拉一把就能够到"的区间。太容易了没有学习发生,太难了只有崩溃。
我得坦白说,在实践中我很难精确判断"这个困难是好的还是坏的"。这个判定本身可能有循环论证的嫌疑——怎么知道困难是合意的?因为它最终有效。怎么知道它会有效?因为它是合意的。但方向至少是清楚的:如果学得很轻松,大概率没在真学;如果学得痛苦但能看到进步,那才是在走。
关键是"能看到进步"。痛苦本身不是目的。
七
回到一个更基本的问题:为什么间隔学习比集中突击有效?为什么睡一觉比通宵有用?
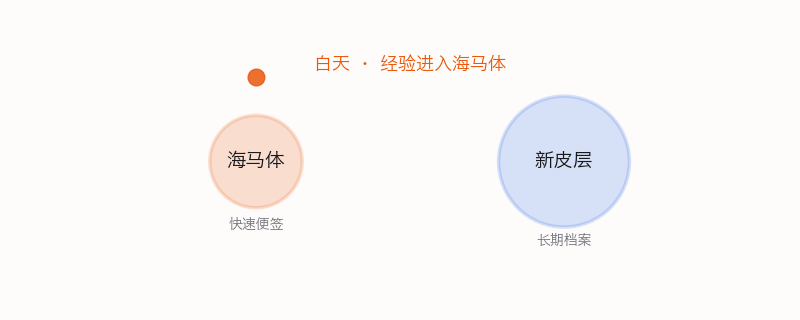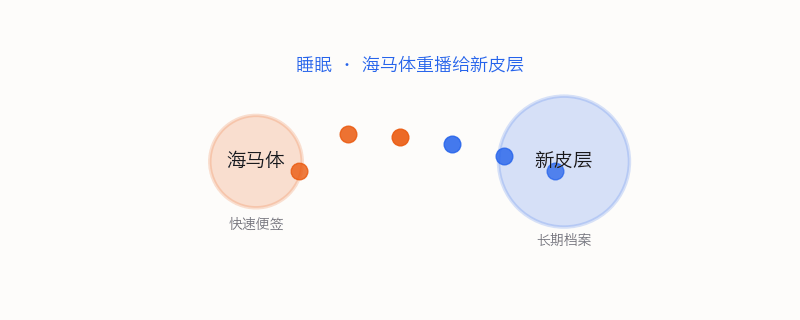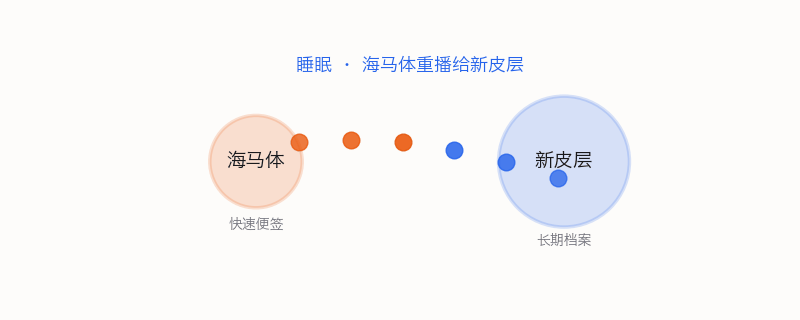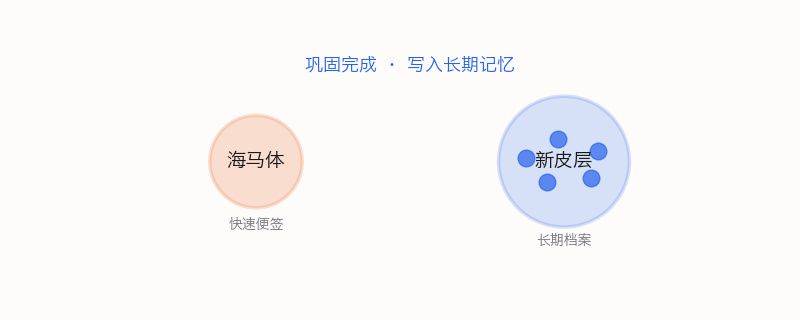
大脑有一个精妙的双系统——计算神经科学家叫它互补学习系统(CLS)。海马体负责快速编码:你今天学的东西先草草记在海马体里,像一个临时便签本,速度快但容量有限,容易被新信息覆盖。新皮层负责慢速巩固:把海马体记下来的东西,慢慢整理、抽象、和已有知识编织在一起,写入长期档案。
关键环节是睡眠。睡觉时海马体把白天记录的信息"重播"给新皮层。一遍一遍地,把经验慢慢写入长期存储。
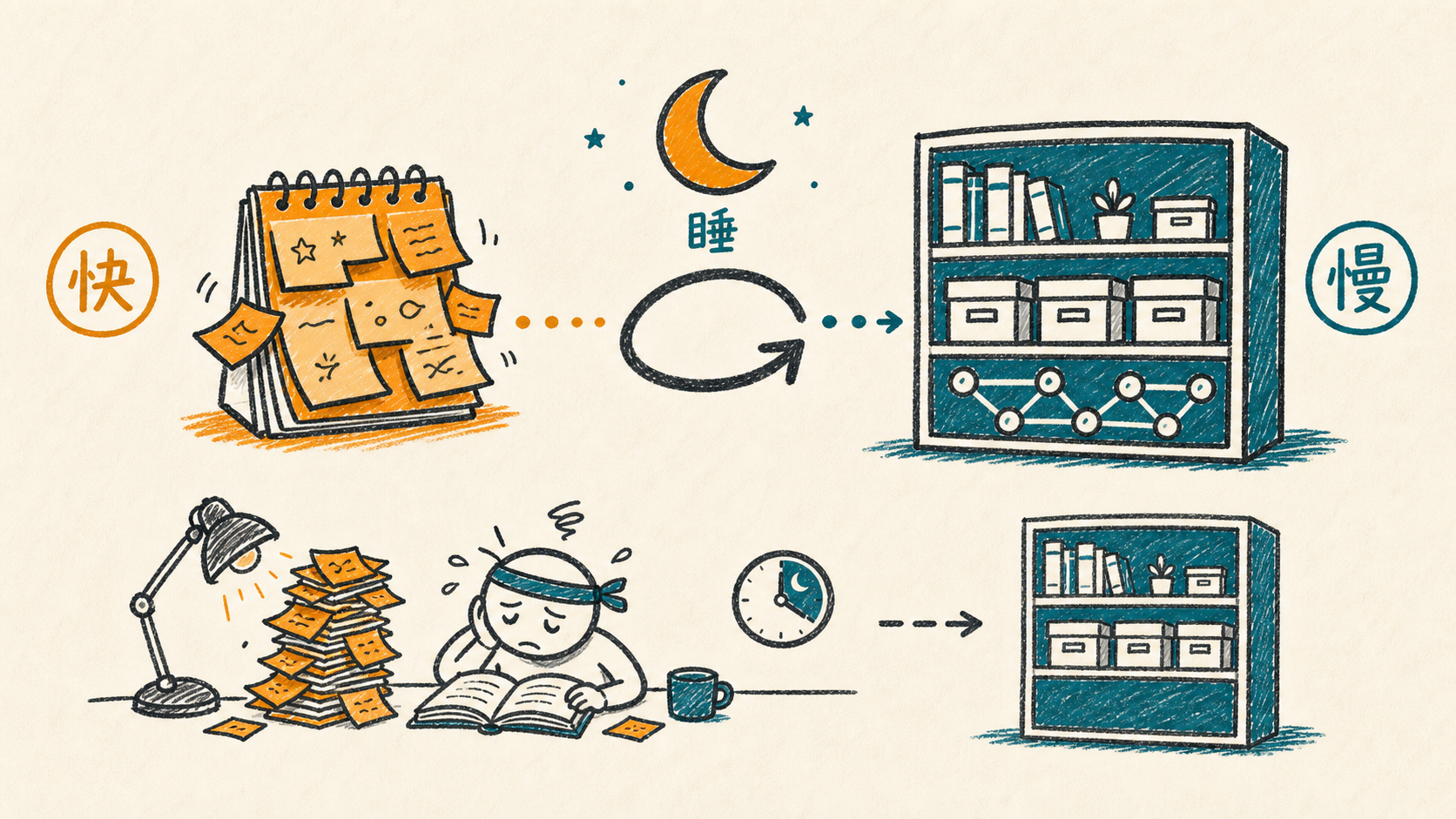
这就解释了为什么考前通宵是灾难性的学习策略——不是因为"休息好了脑子清醒"这么简单,而是你剥夺了大脑把便签转化为长期记忆的窗口。我大学有机化学那次通宵复习,海马体里有新鲜编码,所以第二天考试还行。但没有经过睡眠巩固的记忆,一周后就没了。师兄问我亲核取代反应时的一脸懵,说明那些东西从来就没写进长期存储。
间隔学习有效,一部分原因是每次间隔都给了一个睡眠巩固的窗口。不是一次性往大脑里灌,而是"学一点→睡一觉→再学一点→再睡一觉"——每一轮睡眠都帮你把知识从便签本搬进图书馆。
八
还有一件事我以前没想清楚。
"学会"这个词用起来太随便了。"我学会了有机化学"和"我学会了骑自行车"和"我学会了看人脸色"——这三个"学会"说的根本不是同一种东西。
哲学家 Ryle 在 1949 年就区分了"知道那是什么"(knowing-that)和"知道怎么做"(knowing-how)。Polanyi 又加了一层:默会知识——你知道但说不出来的东西。老中医把脉,手指搭上去就知道是什么脉象,但让他精确描述手指尖感受到什么,他说不清楚。不是不想说,是这种知识不住在语言里。
这意味着"怎么才能真学会"没有万能答案。对陈述性知识——历史年份、化学公式——间隔测试管用。但对程序性知识——弹钢琴、做手术——你需要的是刻意练习:在能力边缘反复练、有即时反馈、有意识调整。对默会知识,可能唯一的路径就是浸泡和时间。
Dreyfus 研究技能获得时发现,从新手到专家有五个阶段,最高阶段的特征是"不经过规则思考就能做对"——不是规则掌握得更熟了,而是根本不再用规则了。就像你开了十年车不会再想"先踩离合再挂挡"。
但经验年数不等于专长。Ericsson 反复强调过这一点:20 年经验的医生不一定比 5 年的好——如果那 20 年只是在重复而没有在边缘挑战自己。时间的流逝不等于学习的发生。
九
说到"表面学会 vs 真正学会",还有一个让我觉得有意思的角度。
Argyris 研究组织学习时发现:组织也会"假学会"。他区分了单环学习和双环学习。单环学习是在不改变底层假设的情况下调整行为——产品卖不好就改广告策略。双环学习是质疑和修改底层假设本身——产品卖不好,问"我们对用户需求的假设是不是错了"。
这跟 Piaget 说的"同化"和"顺应"是一回事。同化是把新信息塞进已有框架——看到新动物说"又一种狗"。顺应是发现框架装不下了,不得不改框架本身——发现那个"狗"其实是狐狸。
不过同化不是坏事。一个有经验的医生把新病例归入已有诊断框架,这完全是正当的"真学会"。只有当问题需要框架本身改变,而框架拒绝改变的时候,同化才变成陷阱。
我们大多数人的问题是几乎从不做顺应。不断把新东西塞进旧框架,直到矛盾大到无法忽视。那个瞬间通常很痛——因为不只是在改一个想法,是在动摇自己赖以理解世界的结构。
还有一件讽刺的事值得一提。89% 的教师相信"学习风格"理论——你是视觉型还是听觉型还是动觉型。但 Pashler 等人的系统综述显示,把教学方法匹配到学生的学习风格偏好上,对学习效果的提升是零。一个专门教别人怎么学习的系统,自己"过拟合"了一个错误的信念还传了几十年。
还有一些我没想清楚的
远迁移。把一个领域学到的东西用到完全不同的领域。Detterman 翻了将近一个世纪的实验文献,结论让人不安:远迁移在实验室里几乎观察不到。
但人类文明本身就是大规模远迁移的产物——数学迁移到物理,物理迁移到工程,工程迁移到日常。如果迁移真的不可能,我们不会坐在这里。
可能的调和是:个体层面的远迁移确实罕见且昂贵——需要深厚的多领域知识、有意识的抽象、足够长的时间。实验室里给被试 30 分钟做的迁移测试,可能根本捕捉不到需要几年才能完成的那种迁移。
说实话我没有确定的答案。但方向可能是这样的:迁移不是自动发生的,它需要你刻意去寻找不同情境间的结构相似性。这很贵。这需要时间。
回到那本书
我现在偶尔还会想起那个翻开荧光笔的晚上。
不一样的是,那种"被骗了"的感觉变了。不是愤怒,更像是一种带着释然的清醒。
荧光笔还在抽屉里。我偶尔还是会划线——但那只是标记"这里值得回来",不再是"我学完了"的仪式。读完之后我会合上书,拿出一张白纸,试着不看书地写下我刚才读到了什么。
写得出来的部分是我的。写不出来的,就是还没学会。
很简单的一个动作。但那种不舒服的感觉——笔停在空白纸上、脑子里一片模糊、不得不承认"我其实没记住"——我现在知道了,那就是学习正在发生的信号。
延伸阅读
-
Soderstrom & Bjork (2015). Learning versus Performance: An Integrative Review. — 如果只读一篇,读这篇。"表现好不等于学会了"这个核心区分的最系统综述。
-
Robert Bjork (1994). Memory and Metamemory Considerations in the Training of Human Beings. — 合意困难概念的源头论文。理解这个概念会动摇你对"学得顺"的全部直觉。
-
Roediger & Karpicke (2006). Test-Enhanced Learning. — 那个"五分钟后 vs 一周后"的实验。数据干净,结论扎心。
-
McClelland, McNaughton & O'Reilly (1995). Why There Are Complementary Learning Systems in the Hippocampus and Neocortex. — CLS 理论原文。解释了为什么大脑需要快慢两套系统。
-
Nassim Taleb (2012). 《反脆弱》 — 不专门讲学习,但"系统通过适度冲击变强"这个原理贯穿全书。合意困难最好的哲学注脚。
-
Piaget (1952). 《儿童智力的起源》 — 同化和顺应的原始论述。理解"真学会"有时意味着打碎旧框架。
-
Vygotsky (1978). 《心智在社会中的形成》 — 最近发展区的概念出处。困难什么时候是"合意的"什么时候是"压垮的"。
-
Gilbert Ryle (1949). 《心的概念》 — knowing-that 和 knowing-how 的区分。看似简单但后续影响了整个认知科学。
-
Michael Polanyi (1966). The Tacit Dimension. — "我们知道的比我们能说出来的多"。不同知识类型有不同的"学会"标准。
-
Pashler et al. (2008). Learning Styles: Concepts and Evidence. — 学习风格迷思的系统拆解。89% 的教师信了零证据的理论。
-
Detterman (1993). The Case for the Prosecution: Transfer as an Epiphenomenon. — 远迁移悲观论的代表作。读完让你对"教育到底教了什么"产生真实的不安。
-
K. Anders Ericsson (1993). The Role of Deliberate Practice in the Acquisition of Expert Performance. — 刻意练习原始论文。但记住 Macnamara 的元分析:刻意练习只解释约 18% 的表现差异。
-
Argyris & Schon (1978). Organizational Learning: A Theory of Action Perspective. — 单环/双环学习的源头。组织如何"假学会"。
-
Walker (2017). 《我们为什么睡觉》 — 睡眠巩固的通俗读物。部分数据有争议但大框架有启发。